第1回RT-CITをオンラン実験でやってみるための勉強会
去年から計画していたZoomによる勉強会をとうとう開催することができました。こういう勉強会って、えいや!と、日程を決めてしまわないと、はなかなか進められないですよね。
ということで、今日の成果と次回の課題などなど、こちらに記録しておこうかと思います。
1.先週対面でちょっと勉強しようとした話(第0回)
実は、先週一緒に勉強会をしようとしているM先生の勤務先の大学に別の要件で遊びに行ったんです!その時、用意していたテキストを進めていこうと思ったんだけど…プログラムをダウンロードする段階でつまづいてしまい、1時間くらい2人で頭を抱えることに…
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/43eec402.7a87bbfd.43eec403.44f98c8b/?me_id=1273418&item_id=15759791&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fvaboo%2Fcabinet%2Fbooks086%2F9784779508523.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

一旦このテキストは諦めて、再度自分たちが何がしたいのかを考えることに。
できること、やりたいこと、できてないことなどなど、2人で持っている知識を出しあって(笑)、エリートにもオンラインで相談して…結局lab.jsを勉強してみようということになりました!
いろんな人がやり方を解説して公開してくれているので、まずは簡単そうなやつから一緒にやって行こうということになりました!ということで、毎週水曜9時半から!Zoomで勉強会を進めていきます!
2.lab.jsをやってみる!
こちらのページを参考にすることにしました。2人ともlab.jsのサイト(?)のページを開いたことがあるだけの状態からスタートしました(笑)
まず最初に、lab.jsをダウンロードするとか、そういうことじゃなくって、ブラウザ上でできるんだぁ…ということを学びました!!
そして、まずは選択反応課題の課題(?)を作ってみようということで、以下のページを見て、そのまんまやってみることにしました!
3.実際にやってみてできたこと失敗したこと
ちゃんと、「Chrome」の最新版を使って、lab.jsのホームページから「Builder」を開いて、「Study(プロジェクト)」→「Screen」→「Content」
そして、下の「+」から「Circle」選びました。
4.次回の予定
2025年1月22日(水)9:30〜10:30
次回は、結果の出力とあわよくばフィードバックです!
お楽しみに❤️
Rで一般化線形混合モデルの分析に挑戦!!
こちらのブログを書いた後、考え方についても、きちんとまとめようと考え、以下の別のブログに記事を書きました。
***
年末から少し勉強を始めていて、統計が得意な友だちにも何度も見てもらって、一般化線形混合モデルの分析をやってみるところまではマスターした!と思っていた私ですが、久しぶりに少し余裕が出てきたので、別のデータを分析してみようとしたのですが…全然うまくいきませんでした。
前回教えてもらったRのコードもすべて記録してあるのに…
半日悩んで、いろいろ検索しまくって、仕方ないので友だちにZoomで私のRstudioの画面を共有して、できているところまで説明している途中で気が付きました。
最初にパッケージをインストールするとき、パッケージの名前を” ”で囲むことを忘れていたんです。
そんな初歩的なミスを…とショックでしたが、自分で気が付けたし、良かったとしたところでしょう(笑)
ということで、私はまだ方法しか理解できておらず、分析の中身をふんわりとしか理解できていないので、せっかくZoomで友だちが見てくれているので、いろいろ教えてもらいました(^^)
前回の復習をして、ちゃんとわかっていないところを再確認し、さらに今回は分析する要因が増えた場合のやり方まで教わって、少しパワーアップです!
次回やろうとしたときに、パッケージをインストールできないという失敗をしないよう、しっかりここに書いておきます!笑
(前回挑戦した時より、パソコンが新しくなっているので、パッケージのインストールをするところからやってみる必要があったのです。)
lmer関数は、線形混合モデルや一般化線形混合モデルの推定計算をする関数だそうで、今回私は一般化線形混合モデルの分析に挑戦するのでちょっとだけ勉強しています(^^)
使い方はこんな感じだそうです。
lmer(Y ~ x1 + x2 (ID|factor), data = data)
まずは、パッケージのインストールと読み込みをします。
lme4パッケージでlmerを用いた分析ができるのですが、p値が計算されません。lmerTestパッケージも一緒に読み込んでおくと、p値を一緒に計算してもらえるようになります。
install.packages(”lme4”)#lme4パッケージのインストール
library(lme4)#lme4パッケージの読み込み
install.packages("lmerTest")#lmerTestパッケージのインストール
library(lmerTest)#lmerTestパッケージの読み込み
1.2水準の一般化線形混合モデルの分析
データを読み込みます。
エクセルで必要な表をコピーして、一番上の行をラベルとして読み込んでもらいます。
read.clip()でもクリップボードのデータを読み込むことができますが、これはanova君を読み込んでいないと使えません。今回は、read,tableという関数を使います。
data <- read.table("clipboard", header = T)#クリップボードのデータをdataに読み込んで一番上をラベルにする
読み込んだファイルはこんな感じでした。

IDを見るとわかりますが、参加者01のデータが2行あって、それをダミー変数で区別できるようになっています。
脳波のデータ(P300、N2、LPP )が目的変数、性格特性の得点(Psychopathy、Machiavellian、Narcissism)が説明変数として、条件(0.5:Positive画像、-0.5:Negative画像)をダミー変数として区別するようにします(性格特性とダミー変数は、中心化してあります)。
そうして、性格特性が条件ごとの脳波データにどのように影響するのかについての分析を行います。
まずは、性格特性(Psychopathy)が条件ごとの脳波データ(P300)にどのように影響するのかについて分析してみます。
fit <- lmer(P300 ~ Psychopathy * (1|ID)+(-1+dummy|ID), data)#一般化線形混合モデルによる分析
summary(fit)#結果を表示させる
結果はこんな風にでてきました。
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: P300 ~ Psychopathy * (1 | ID) + (-1 + dummy | ID)
Data: data
REML criterion at convergence: 139.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.49145 -0.37942 -0.09697 0.24262 1.81294
Random effects:
Groups Name Variance Std.Dev.
ID (Intercept) 3.2540 1.8039
ID.1 dummy 0.5664 0.7526
Residual 0.7901 0.8889
Number of obs: 36, groups: ID, 18
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 3.2534 0.4502 16.0004 7.226 2.02e-06 ***
Psychopathy -0.0286 0.0962 16.0004 -0.297 0.77 ←有意差なし
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr)
Psychopathy 0.000
赤字のところを他の脳波成分や性格特性のデータに入れ替えて、分析をやってみます!!
2.3水準の一般化線形混合モデルの分析
ここまでのやり方は、条件が2つの場合のやり方です。
具体的には、呈示したPositive刺激とネガティブ刺激の差を見ていくものでした。
しかし、実はPositive刺激とNegative刺激だけでなく、Neutral刺激も呈示していたのです。
そうなると、ダミー変数をどう指定したらいいのかわからなかったのですが、やり方を教えてもらいました!
こういう場合は、ダミー変数を2つ用意すると良いそうです。
どんな仮説を設定しているかによって、ダミー変数の作り方が変わってくるようなのですが、今回のデータでは、統制条件であるNeutralがあるので、Neutral刺激とPositive刺激の比較、Neutral刺激とNegative刺激の比較ができるようにダミー変数を作りました。
読み込んだデータはこちら。

さっきのデータとほぼ一緒ですが、IDのところの参加者01が3行になっています。そして、ダミー変数が2つあります。上からPositive、Neutral、Negativeになているので、統制条件であるNeutralが常に0になっていて、比較対象のPositiveが1になるdummy1とNegativeが1になるdummy2があります。
先ほどとほぼ同じですが、脳波のデータ(P300、N2、LPP )が目的変数、性格特性の得点(Psychopathy、Machiavellian、Narcissism)が説明変数として、条件(Positive、Neutral、Negative)をダミー変数として区別するようにします(性格特性とダミー変数は、中心化してあります)。
そうして、性格特性が3つの条件ごとの脳波データにどのように影響するのかについての分析を行います。
まずは、性格特性(Psychopathy)が3つの条件ごとの脳波データ(P300)にどのように影響するのかについて分析してみます。
fit <- lmer(P300 ~ dummy1 + dummy2 + Psychopathy + dummy1 : Psychopathy + dummy2 : Psychopathy +(1|ID)+(-1+dummy1|ID)+(-1+dummy2|ID), data) > #dummy変数が2つの場合の一般化線形混合モデルによる分析
summary(fit)#結果を表示させる
結果はこんな風にでてきました。
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: P300 ~ dummy1 + dummy2 + Psychopathy + dummy1:Psychopathy + dummy2:Psychopathy +
(1 | ID) + (-1 + dummy1 | ID) + (-1 + dummy2 | ID)
Data: data
REML criterion at convergence: 205.3
Scaled residuals:
Min 1Q Median 3Q Max
-1.86581 -0.37546 -0.04477 0.37409 1.48376
Random effects:
Groups Name Variance Std.Dev.
ID (Intercept) 2.6391 1.6245
ID.1 dummy1 1.3391 1.1572
ID.2 dummy2 0.0000 0.0000
Residual 0.8866 0.9416
Number of obs: 54, groups: ID, 18
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 3.43917 0.44257 21.44835 7.771 1.13e-07 ***
dummy1 -0.13250 0.41582 22.12539 -0.319 0.753
dummy2 -0.24078 0.31386 15.34604 -0.767 0.455
Psychopathy -0.06065 0.09456 21.44835 -0.641 0.528
dummy1:Psychopathy 0.08142 0.08885 22.12539 0.916 0.369
dummy2:Psychopathy -0.01752 0.06706 15.34604 -0.261 0.797
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) dummy1 dummy2 Psychp dmm1:P
dummy1 -0.268
dummy2 -0.355 0.377
Psychopathy 0.000 0.000 0.000
dmmy1:Psych 0.000 0.000 0.000 -0.268
dmmy2:Psych 0.000 0.000 0.000 -0.355 0.377
optimizer (nloptwrap) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')
どこにも有意差はなかったので、ちょっと差がでていた条件の結果を紹介しますね。
こちらは、サイコパシー得点が3つの条件ごとのN2にどのように影響するのかについての分析を行った結果です。
> fit <- lmer(N2 ~ dummy1 + dummy2 + Psychopathy + dummy1 : Psychopathy + dummy2 : Psychopathy +(1|ID)+(-1+dummy1|ID)+(-1+dummy2|ID), data) > summary(fit)#結果を表示させる Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest'] Formula: N2 ~ dummy1 + dummy2 + Psychopathy + dummy1:Psychopathy + dummy2:Psychopathy + (1 | ID) + (-1 + dummy1 | ID) + (-1 + dummy2 | ID) Data: data REML criterion at convergence: 206.8 Scaled residuals: Min 1Q Median 3Q Max -1.81854 -0.37034 0.00532 0.52450 1.41051 Random effects: Groups Name Variance Std.Dev. ID (Intercept) 1.2283 1.1083 ID.1 dummy1 0.9072 0.9524 ID.2 dummy2 0.9536 0.9765 Residual 1.1235 1.0600 Number of obs: 54, groups: ID, 18 Fixed effects: Estimate Std. Error df t value Pr(>|t|) (Intercept) -2.27339 0.36146 18.30366 -6.289 5.8e-06 *** dummy1 0.06644 0.41861 10.00213 0.159 0.8770 dummy2 1.09028 0.42168 22.74326 2.586 0.0166 * Psychopathy 0.11356 0.07723 18.30366 1.470 0.1584 dummy1:Psychopathy -0.05828 0.08944 10.00213 -0.652 0.5293 dummy2:Psychopathy -0.09522 0.09010 22.74326 -1.057 0.3017 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Correlation of Fixed Effects: (Intr) dummy1 dummy2 Psychp dmm1:P dummy1 -0.413 dummy2 -0.410 0.354 Psychopathy 0.000 0.000 0.000 dmmy1:Psych 0.000 0.000 0.000 -0.413 dmmy2:Psych 0.000 0.000 0.000 -0.410 0.354
dummy2のところに有意差が出ています。
dummy2には、NeutralとNegativeの比較をする変数が入っているので、dummy2が有意であるということは、「サイコパシー得点に関わらず、N2の値はNegative刺激に対するものよりもNeutral刺激に対するものの方が大きい」ということが言えます。
3.まとめ
今回使ったコード(スクリプト?)のまとめです。
これをコピーして、左上のペインに貼り付けて、「→Run」のボタンを押すと進んでいきます(^^)
ダミー変数が1つの場合
install.packages(”lme4”)#lme4パッケージのインストール
library(lme4)#lme4パッケージの読み込み
install.packages("lmerTest")#lmerTestパッケージのインストール
library(lmerTest)#lmerTestパッケージの読み込み
data <- read.table("clipboard", header = T)#クリップボードのデータをdataに読み込んで一番上をラベルにする
fit <- lmer(P300 ~ Psychopathy * (1|ID)+(-1+dummy|ID), data)#一般化線形混合モデルによる分析
summary(fit)#結果を表示させる
ダミー変数が2つの場合
install.packages(”lme4”)#lme4パッケージのインストール
library(lme4)#lme4パッケージの読み込み
install.packages("lmerTest")#lmerTestパッケージのインストール
library(lmerTest)#lmerTestパッケージの読み込み
data <- read.table("clipboard", header = T)#クリップボードのデータをdataに読み込んで一番上をラベルにする
fit <- lmer(P300 ~ dummy1 + dummy2 + Psychopathy + dummy1 : Psychopathy + dummy2 : Psychopathy +(1|ID)+(-1+dummy1|ID)+(-1+dummy2|ID), data) > #dummy変数が2つの場合の一般化線形混合モデルによる分析
summary(fit)#結果を表示させる
これで、次回から1人で分析ができる(はず)!!
Rで分散分析に挑戦!!
1つ前のブログで、t検定も分散分析も一気に書いちゃおうと思ったのですが、書き始めるとなかなか記録しておくことも多かったり、「あれ?どうだっけ?」なんて思うところも多かったので、なかなか進みませんでした。
やっぱり、1つずつきちんとまとめておかないとだめですね。
ということで、今日は分散分析のやりかたをまとめます。
(前回まとめたt検定に挑戦の記事はこちらから。)
Rでt検定に挑戦!! - yuki’s diary (hatenablog.com)
分散分析をする時は、anova君という関数??を使います。
他にもやり方はあるみたいなんですが、誰に聞いてもとりあえずanova君だというので、とにかくやってみます!
まず最初に、以下の井関龍太先生のHPでanova君をダウンロードします。
ANOVA君 - 井関龍太のページ (xdomain.jp)
ダウンロード出来たら、Rのワーキングディレクトリに入れておきます。
私は、最初に設定したR_practiceっていうフォルダに入れました。
続いて、source関数を使ってanova君を読み込みます。
パッケージを読み込むときとはやり方が違うので注意です。
source("anovakun_487.txt")
私がダウンロードした時は、487でした。ファイルの名前をよく見て入力してくださいね。
私は、””を忘れがちなので、エラーがでたら、ちゃんと””入れているか確認します笑
実行すると、右上のEvbironment paneにanova君に入っている情報が表示されます。

これで準備はOKです。
あとは、どんな条件で分散分析をするかです。
分散分析を実行するには、anovakun関数を使用して、以下のように書きます。
anovakun(データ、”要因計画の型”,各要因の水準数,…)
要因計画の型のところの書き方がちょっと難しいです。
sを挟んで左側に参加者間要因、右側に参加者内要因の文字が来るように書きます。
3要因参加者間計画であれば以下のようになります。
anovakun(data,"ABCs", 2,2,2)
2つの参加者間要因と1つの参加者内要因の混合計画であれば以下のようになります。
anovakun(data,"ABsC",2,2,2)
3つの参加者内要因計画であれば以下のようになります。
anovakun(data,"sABC",2,2,2)
そして、多重比較の方法も指定ができます。
デフォルトだとShaffer法ですが、Holmの方法(holm=T)やHolland-Copenhaverの方法(hc=T)も指定できるようです。
私は、Bonferroni法がよかったのですが、anova君では無理みたいです。
なので、今回は特に指定せずにやってみます。
さらに、効果量を一緒に算出してほしい場合も指定します。
偏η2乗:peta=T
オメガ2乗:omega=T
私は、いつも偏η2乗を記載しているので、いつも通り偏η2乗を使ってみます。
では、実際に、私のデータでやってみます!
(1)1要因参加者内計画の分散分析
私のこんなデータを分析してみます。

それぞれの刺激(Target, Relevant, Irrelevant)に対するP300の値が入っています。
t検定の時は、どーんとデータを入れて、ラベルを選んで検定って感じでしたが、分散分析の場合は(anova君の場合?)、事前にエクセルで分析しやすいようにデータセットを作っておく必要があります。
逆に、ここさえ間違えなければ、難しいところはあんまりないと思いました。
1要因分散分析の計画は以下のようになります。
A:Stimulus(3:Target・Relevant・Irrelevant)
data <- read.clip()
anovakun(data,"sA",3, peta=T)
とってもシンプルです。
その結果がこちら。
[ sA-Type Design ]
This output was generated by anovakun 4.8.7 under R version 4.2.0.
It was executed on Mon Nov 14 11:40:27 2022.
<< DESCRIPTIVE STATISTICS >>
== The number of removed case is 1. ==
---------------------------
A n Mean S.D.
---------------------------
a1 57 17.9850 6.0367
a2 57 11.6341 3.9822
a3 57 10.1083 4.1535
---------------------------
<< SPHERICITY INDICES >>
== Mendoza's Multisample Sphericity Test and Epsilons ==
-------------------------------------------------------------------------
Effect Lambda approx.Chi df p LB GG HF CM
-------------------------------------------------------------------------
A 0.0000 48.6962 2 0.0000 *** 0.5000 0.6299 0.6377 0.6353
-------------------------------------------------------------------------
LB = lower.bound, GG = Greenhouse-Geisser
HF = Huynh-Feldt-Lecoutre, CM = Chi-Muller
<< ANOVA TABLE >>
----------------------------------------------------------------
Source SS df MS F-ratio p-value p.eta^2
----------------------------------------------------------------
s 3096.9323 56 55.3024
----------------------------------------------------------------
A 1989.3992 2 994.6996 139.6155 0.0000 *** 0.7137
s x A 797.9514 112 7.1246
----------------------------------------------------------------
Total 5884.2829 170 34.6134
+p < .10, *p < .05, **p < .01, ***p < .001
<< POST ANALYSES >>
< MULTIPLE COMPARISON for "A" >
== Shaffer's Modified Sequentially Rejective Bonferroni Procedure ==
== The factor < A > is analysed as dependent means. ==
== Alpha level is 0.05. ==
---------------------------
A n Mean S.D.
---------------------------
a1 57 17.9850 6.0367
a2 57 11.6341 3.9822
a3 57 10.1083 4.1535
---------------------------
---------------------------------------------------------
Pair Diff t-value df p adj.p
---------------------------------------------------------
a1-a3 7.8767 12.9106 56 0.0000 0.0000 a1 > a3 *
a1-a2 6.3509 11.2863 56 0.0000 0.0000 a1 > a2 *
a2-a3 1.5258 6.1731 56 0.0000 0.0000 a2 > a3 *
---------------------------------------------------------
output is over --------------------///
A(刺激)の主効果(P< .01)が有意で、多重比較の結果もA1 > A2 > A3ときれいに有意差が出ているようです。
良かったよかった。
(2)2要因参加者間内計画の混合計画
私のこんなデータを分析してみます。

V1のところに、初犯か累犯かの情報が入っていて、V2~V4 のところには、それぞれの刺激(Target, Relevant, Irrelevant)に対するP300の値が入っています。
逆に、ここさえ間違えなければ、難しいところはあんまりないと思いました。
2要因分散分析の計画は以下のようになります。
A:Crime(2:初犯・累犯)×B:Stimulus(3:Target・Relevant・Irrelevant)
では、やってみます!
source("anovakun_487.txt") #anova君読み込み
data_polygraph <- read.clip() #データの読み込み
anovakun(data_polygraph,"AsB",2,3, peta=Tpeta=T)
結果はこんな感じです。
[ AsB-Type Design ]
This output was generated by anovakun 4.8.7 under R version 4.2.0.
It was executed on Mon Nov 14 11:27:43 2022.
<< DESCRIPTIVE STATISTICS >>
== The number of removed case is 1. ==
-------------------------------
A B n Mean S.D.
-------------------------------
a1 b1 22 17.2749 4.9245
a1 b2 22 11.3770 4.1141
a1 b3 22 9.5434 4.4729
a2 b1 35 18.4314 6.6717
a2 b2 35 11.7957 3.9491
a2 b3 35 10.4634 3.9650
-------------------------------
<< SPHERICITY INDICES >>
== Mendoza's Multisample Sphericity Test and Epsilons ==
-------------------------------------------------------------------------
Effect Lambda approx.Chi df p LB GG HF CM
-------------------------------------------------------------------------
B 0.0000 50.9902 5 0.0000 *** 0.5000 0.6275 0.6353 0.6328
-------------------------------------------------------------------------
LB = lower.bound, GG = Greenhouse-Geisser
HF = Huynh-Feldt-Lecoutre, CM = Chi-Muller
<< ANOVA TABLE >>
== This data is UNBALANCED!! ==
== Type III SS is applied. ==
------------------------------------------------------------------
Source SS df MS F-ratio p-value p.eta^2
------------------------------------------------------------------
A 28.0346 1 28.0346 0.5024 0.4814 ns 0.0091
s x A 3068.8977 55 55.7981
------------------------------------------------------------------
B 1862.3603 2 931.1802 128.9860 0.0000 *** 0.7011
A x B 3.8357 2 1.9178 0.2657 0.7672 ns 0.0048
s x A x B 794.1157 110 7.2192
------------------------------------------------------------------
Total 5884.2829 170 34.6134
+p < .10, *p < .05, **p < .01, ***p < .001
<< POST ANALYSES >>
< MULTIPLE COMPARISON for "B" >
== Shaffer's Modified Sequentially Rejective Bonferroni Procedure ==
== The factor < B > is analysed as dependent means. ==
== Alpha level is 0.05. ==
---------------------------
B n Mean S.D.
---------------------------
b1 57 17.8532 6.0367
b2 57 11.5864 3.9822
b3 57 10.0034 4.1535
---------------------------
---------------------------------------------------------
Pair Diff t-value df p adj.p
---------------------------------------------------------
b1-b3 7.8498 12.4189 55 0.0000 0.0000 b1 > b3 *
b1-b2 6.2668 10.7853 55 0.0000 0.0000 b1 > b2 *
b2-b3 1.5830 6.2343 55 0.0000 0.0000 b2 > b3 *
---------------------------------------------------------
output is over --------------------///
(3)3要因参加者間内計画の混合計画
私のこんなデータを分析してみます。

上記のデータにmovieという項目が増えただけです。
ポリグラフ検査の前に事件特定のための動画を見たかどうかという条件を加えます。
これは、参加者間条件なので、以下のような計画になります。
A:Crime(2:初犯・累犯)×B:Movie(2:RM・NRM)×C:Stimulus(3:Target・Relevant・Irrelevant)
では、やってみます!
> anovakun(data_polygraph6,"ABsC",2,2,3, peta=T)
結果はこちら。
[ ABsC-Type Design ]
This output was generated by anovakun 4.8.7 under R version 4.2.0.
It was executed on Mon Nov 14 11:30:46 2022.
<< DESCRIPTIVE STATISTICS >>
== The number of removed case is 1. ==
-----------------------------------
A B C n Mean S.D.
-----------------------------------
a1 b1 c1 12 15.5252 3.2102
a1 b1 c2 12 10.3381 2.7285
a1 b1 c3 12 9.0086 3.8308
a1 b2 c1 10 19.3746 5.9168
a1 b2 c2 10 12.6238 5.2180
a1 b2 c3 10 10.1851 5.2828
a2 b1 c1 18 17.4746 6.5534
a2 b1 c2 18 12.3498 3.9385
a2 b1 c3 18 10.5027 3.7567
a2 b2 c1 17 19.4445 6.8437
a2 b2 c2 17 11.2089 3.9934
a2 b2 c3 17 10.4219 4.2907
-----------------------------------
<< SPHERICITY INDICES >>
== Mendoza's Multisample Sphericity Test and Epsilons ==
-------------------------------------------------------------------------
Effect Lambda approx.Chi df p LB GG HF CM
-------------------------------------------------------------------------
C 0.0000 49.7057 11 0.0000 *** 0.5000 0.6231 0.6309 0.6282
-------------------------------------------------------------------------
LB = lower.bound, GG = Greenhouse-Geisser
HF = Huynh-Feldt-Lecoutre, CM = Chi-Muller
<< ANOVA TABLE >>
== This data is UNBALANCED!! ==
== Type III SS is applied. ==
----------------------------------------------------------------------
Source SS df MS F-ratio p-value p.eta^2
----------------------------------------------------------------------
A 21.1575 1 21.1575 0.3775 0.5415 ns 0.0071
B 72.7326 1 72.7326 1.2979 0.2597 ns 0.0239
A x B 48.2346 1 48.2346 0.8607 0.3577 ns 0.0160
s x A x B 2970.0658 53 56.0390
----------------------------------------------------------------------
C 1887.6391 2 943.8195 136.9145 0.0000 *** 0.7209
A x C 3.7986 2 1.8993 0.2755 0.7597 ns 0.0052
B x C 49.4500 2 24.7250 3.5867 0.0311 * 0.0634
A x B x C 8.3827 2 4.1913 0.6080 0.5463 ns 0.0113
s x A x B x C 730.7105 106 6.8935
----------------------------------------------------------------------
Total 5884.2829 170 34.6134
+p < .10, *p < .05, **p < .01, ***p < .001
<< POST ANALYSES >>
< MULTIPLE COMPARISON for "C" >
== Shaffer's Modified Sequentially Rejective Bonferroni Procedure ==
== The factor < C > is analysed as dependent means. ==
== Alpha level is 0.05. ==
---------------------------
C n Mean S.D.
---------------------------
c1 57 17.9547 6.0367
c2 57 11.6301 3.9822
c3 57 10.0296 4.1535
---------------------------
---------------------------------------------------------
Pair Diff t-value df p adj.p
---------------------------------------------------------
c1-c3 7.9252 12.6861 53 0.0000 0.0000 c1 > c3 *
c1-c2 6.3246 11.2176 53 0.0000 0.0000 c1 > c2 *
c2-c3 1.6006 6.4563 53 0.0000 0.0000 c2 > c3 *
---------------------------------------------------------
< SIMPLE EFFECTS for "B x C" INTERACTION >
-------------------------------
B C n Mean S.D.
-------------------------------
b1 c1 30 16.6948 5.4798
b1 c2 30 11.5451 3.5947
b1 c3 30 9.9050 3.7939
b2 c1 27 19.4186 6.3986
b2 c2 27 11.7329 4.4411
b2 c3 27 10.3342 4.5829
-------------------------------
--------------------------------------------------------------------------
Effect Lambda approx.Chi df p LB GG HF CM
--------------------------------------------------------------------------
C at b1 0.0000 32.0337 5 0.0000 *** 0.5000 0.5952 0.6065 0.5976
C at b2 0.0001 17.3807 5 0.0038 ** 0.5000 0.6584 0.6805 0.6680
--------------------------------------------------------------------------
LB = lower.bound, GG = Greenhouse-Geisser
HF = Huynh-Feldt-Lecoutre, CM = Chi-Muller
--------------------------------------------------------------------
Source SS df MS F-ratio p-value p.eta^2
--------------------------------------------------------------------
B at c1 113.7479 1 113.7479 3.1598 0.0812 + 0.0563
Er at c1 1907.9217 53 35.9985
--------------------------------------------------------------------
B at c2 4.4019 1 4.4019 0.2758 0.6016 ns 0.0052
Er at c2 845.7883 53 15.9583
--------------------------------------------------------------------
B at c3 4.0328 1 4.0328 0.2257 0.6367 ns 0.0042
Er at c3 947.0663 53 17.8692
--------------------------------------------------------------------
C at b1 716.0786 2 358.0393 49.8397 0.0000 *** 0.6403
s x C at b1 402.2937 56 7.1838
--------------------------------------------------------------------
C at b2 1189.3224 2 594.6612 90.5345 0.0000 *** 0.7836
s x C at b2 328.4168 50 6.5683
--------------------------------------------------------------------
+p < .10, *p < .05, **p < .01, ***p < .001
< MULTIPLE COMPARISON for "C at b1" >
== Shaffer's Modified Sequentially Rejective Bonferroni Procedure ==
== The factor < C at b1 > is analysed as dependent means. ==
== Alpha level is 0.05. ==
---------------------------------------------------------
Pair Diff t-value df p adj.p
---------------------------------------------------------
c1-c3 6.7443 7.6391 28 0.0000 0.0000 c1 > c3 *
c1-c2 5.1559 6.5522 28 0.0000 0.0000 c1 > c2 *
c2-c3 1.5883 5.0742 28 0.0000 0.0000 c2 > c3 *
---------------------------------------------------------
< MULTIPLE COMPARISON for "C at b2" >
== Shaffer's Modified Sequentially Rejective Bonferroni Procedure ==
== The factor < C at b2 > is analysed as dependent means. ==
== Alpha level is 0.05. ==
---------------------------------------------------------
Pair Diff t-value df p adj.p
---------------------------------------------------------
c1-c3 9.1060 10.3958 25 0.0000 0.0000 c1 > c3 *
c1-c2 7.4932 9.3302 25 0.0000 0.0000 c1 > c2 *
c2-c3 1.6128 4.1294 25 0.0004 0.0004 c2 > c3 *
---------------------------------------------------------
output is over --------------------///
Rでt検定に挑戦!!
10年間研究業界にいなかった私は、統計分析ができません笑
当時は、SPSSを使って分析をしていたわけですが、最近はSPSSはお医者さんしか使ってないそうです。
(↑それ本当?ちょっと疑っています)
ということで、HADかRを使った分析ができるようになる必要があります。
実は、夏休みの大学院生の集中講義で、HADを使った統計の授業があったので、こっそり受講してみて、HADはちょっとわかったようなわからんような…。
慣れてきたらすごく便利だというのはわかる上で、まだちょっと慣れません。
こういう困ったときでないと、なかなか勉強はできないので、昨日今日とRでの分析の勉強をしてみました。
そしてなんと、t検定と分散分析に成功したので、やり方を忘れないようにこちらにメモしておきます(^^)
「R t検定」とかで調べると、たくさんやり方が紹介してあるんですが、私は、データの読み込みのところがちょっとうまく理解できておらず、ちょっと難航しました。
データの読み込み方も忘れないように色々書いておこうと思います!
1.データの読み込み
① コピーしたデータを読み込む
data <- read.clip()
エクセル等のデータをコピーした状態で、console paneでこれを実行すると、コピーしたデータをdataというオブジェクトに読み込むことができます。
dataのところは、好きな名前をつけることができるので、私の場合polygraph_dataとか、P300_dataのように、もうちょっとわかりやすいタイトルを付ける方が良さそうです。
今のところ、私はこれが一番便利だと思います!
私は、生理指標なんかを扱う実験をすることが多いので、そんなにたくさんのデータを使うこともないので、それが何のデータがだったかわからなくなる心配もありません。
ただ、質問紙のデータなど、たくさんのデータを分析する際には、以下の方法の方が良いみたいです。
本当に読み込めているか心配なので、
View(data)
を実行すると、source paneにdataに入っているデータを表示させることができます。
②csvのデータを読み込む
CSVファイルを読み込む場合は、読み込むファイルをRのプロジェクトと同じフォルダに入れておくと良いです。私は、R_practiceというフォルダを作っているので、そこに置くようにしています。そして、read_csvという関数(?)を使います。ファイル名がpolygraph.csvの場合は、以下のように入力してから実行します。
data <- read_csv("polygraph.csv")
これで、dataというオブジェクトにpolygraph.csvのデータを読み込むことが出来ました。
③Excelのデータを読み込む
Excelファイルを読み込む場合は、新しいパッケージをインストールする必要があります。
install.packages("readxl")
library(readxl)
続いて、ファイルを読み込むときはこちら
data <- read_excel("polygraph.xlsx")
私は、パッケージをインストールする時に、ダブルクオーテーションを忘れがちなので、エラーがあったら、そこをチェックしてみると良いです。
2.t検定
t検定は、2つの平均値の差を調べる検定(だと理解しています)です。
Rでt検定を行うときは、t.test()を使うようなのですが、()の中をどんなふうに書くのかがちょっと難しいと感じました。
t.test(従属変数 ~ 独立変数, data = データフレーム名)
データフレーム名というのが、データの読み込みで取り込んだデータの名前のことで、読み込んだら右上のEnvironment paneに表示されています。
私のポリグラフ検査のデータを例に説明してみますね。

(1)対応のないt検定
左側からcrime(初犯と累犯がいます)、movie(実験動画と統制動画があります)、それから3つの刺激(Target, Relevant, Irrelevant)に対する脳波のピークの値(P300 Peak amplitude)のデータがあります。
今回は、初犯と累犯では、Target刺激に対する脳波のデータに差があるかどうかを調べるt検定をしてみます。
(絶対ないですけど笑)
そうすると、従属変数はtargetになり、独立変数はcrimeになりますね。
早速やってみます!
エクセルのファイルを作っていたので、まずはエクセルファイルを読み込みます!
data_polygraph <- read_excel("polygraph.xlsx")
を実行して、data_targetに上記のデータを取り込みます。
t.test(target ~ crime, data = data_polygraph)
これを実行します!
結果はこちら。
> t.test(target ~ crime, data = data_target)
Welch Two Sample t-test
data: target by crime
t = -0.75058, df = 53.459, p-value = 0.4562
alternative hypothesis: true difference in means between group 1st and group RO is not equal to 0
95 percent confidence interval:
-4.246336 1.933354
sample estimates:
mean in group 1st mean in group RO
17.27491 18.43140
結果にも記載してありますが、Welchのt検定をしてくれています。
対応のない2つの差の検定ですね。
思った通り、初犯者と累犯者の間にはTarget刺激に対するP300に差はないようです。
(厳密に言うと、差がないというよりは差があるとは言えない…なのかもしれません。)
やっている途中で気が付いたのですが、
データを取り込んだ後、attach()という関数を使うと、ヘッダーをそのまま変数名のように使うことができるようです。具体的にはこんな感じです。
data_polygraph <- read_excel("polygraph.xlsx")
attach(data_polygraph)
t.test(target ~ crime)
attach()でdata_polygraphのヘッダーを変数として使えるようになったので、t.test()の中でデータフレームを指定しなくても、そのまま分析できます。
1つだけt検定してみるだけなら、どっちでも良さそうですが、1つのエクセルシートに色々データがあって、それを分析するとなると、attach()を使うと便利そうです。
(2)対応のあるt検定
対応のあるデータということで、さっきのdata_polygraphの中のrelevantとirrelevantのデータを比較してみます。
一応、データを読み込んで、ヘッダーを変数として使えるようにするところから。
data_polygraph <- read_excel("polygraph.xlsx")
attach(data_polygraph)
対応のあるt検定は、2つのデータセットを指定して、最後にpaired = Tを付けるそうです(ちなみに、最後にpaired = Fをつけると対応のないt検定になるようです)。
t.test(データセット1,データセット2,paired = T)
早速やってみます!
relevantとirrelevantを比較するので、こうなります。
> t.test(relevant, irrelevant, paired=TRUE)
結果はこちら。
> t.test(relevant, irrelevant, paired=TRUE)
Paired t-test
data: relevant and irrelevant
t = 6.1731, df = 56, p-value = 7.936e-08
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
1.030645 2.020899
sample estimates:
mean difference
1.525772
p-value = 7.936e-08 となっていますが、これは桁数が多すぎるだけで、計算してみると「0.00000007936」でした。しっかり差がありそうです。
一応、簡単に結果の見方もメモしておきます。
t = t値
df = 自由度
p-value = p値
95percent confidence interval : 95%信頼区間
長くなったので、分散分析は次回にします(^^)/
EEGLABで脳波解析に挑戦④

のろのろですが、分析をすすめています。
本を読んでもわからないところは、ハズバンドにも相談しています。
ありがとう。
これまでの分析はこちら↓を見てね。
1.イベントファイルの作成
2.脳波ファイルの整理
3.EEGでの分析①②③
前回までにエポックを区切るところまでやっているので、今日はエポックリジェクションから始めます!
脳波解析入門を読みながら分析を進めているのですが、なぜか私のEEGLABでは、エポックリジェクションがうまくいかず、仕方がないのでコードを書くことにしました…。
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/21d75f9b.303e68cd.21d75f9c.00f41766/?me_id=1213310&item_id=20174735&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F1187%2F9784130121187_1_106.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
1.エポックリジェクション
ハズバンドに見てもらいながら作ったコードがこちら。
i = 0;
rej_filename = ['sub10',num2str(i,'%02d'),'_rej.set'];
EEG = pop_saveset( EEG, 'filename',rej_filename,'filepath','C:\Users\itoyu_000\OneDrive\Documents\MATLAB');
eeglab redraw
これを、MATLABのコマンドウィンドウに貼り付けてエンターするだけです。
ここでようやく、最初からコードが書ければ、めちゃくちゃ分析がらくちんなんじゃないか?と、コードを最初から書いちゃう人の気持ちを想像することができました笑
最初の i = 0; のところは、参加者の番号を入れるようにしました。
今回は、予備実験のデータを使ってやってみているので、参加者番号00としました。
2行目は、ファイルの名前の付け方です。sub1000‗rej.setというファイル名で保存されるように設定しています。1行目のi=0をi=1に変更すると、ファイル名sub1001_rej.setとなります。
3行目は、どういうルールでリジェクトするかを書いています。EEGの中に、今EEGLABで選択しているファイルが入っていて、次の1はローデータということ(コンポーネントデータであれば0になります)、その次はリジェクトする周波数なので、-100~100として、範囲は、私はー200ms~800msなので秒に直して-0.2,0.8としています。その次の2は、データをそのまま上書きして、最後の1ですぐにリジェクトするという感じです。
4行目で、これらのデータを上書きして、
6行目で、ファイル名を付けて、保存場所を設定しておしまいという感じです。
7行目のeeg_checksetっていうのは、よくわからないのだけど、定期的に出てくるので、EEGの構造に問題がないかチェックしてるみたいです!
eeglab redrawは、eeglabのGUIに現在の状態を反映させるために再読み込みするコードなようです。
MATLABでなんかやっていて、わからなくなったら、わからないコードのところにカーソルを持って行ってF1を押すと、ヘルプが出てきてくれるので、安心です🐍
2.刺激の選択
ここから、それぞれの刺激を選んで、刺激ごとの加算平均波形を出力することが出来ます!
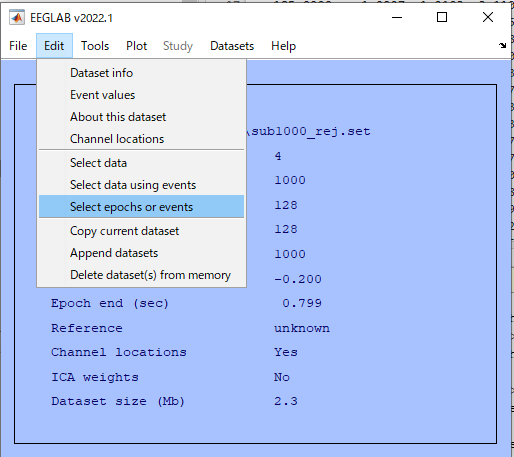
Select eventsのウィンドウが表示されるので、typeの右側の ... のところをクリックして、加算したいタイプを選びます。
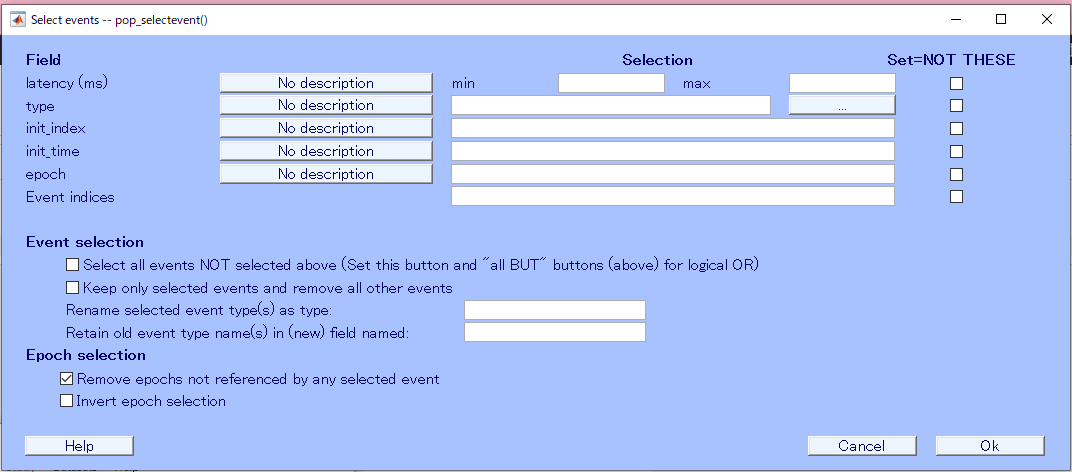
私は、このように6種類の刺激を出しているので、今回はTargetを選んでみます。

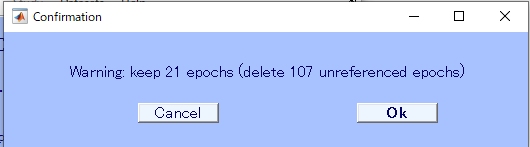
Target が21個あって、それ以外の107個のデータは消しちゃってもいいかと聞かれたので、OKをクリックします。
それが何のデータかわかるように名前を付けて、保存します。
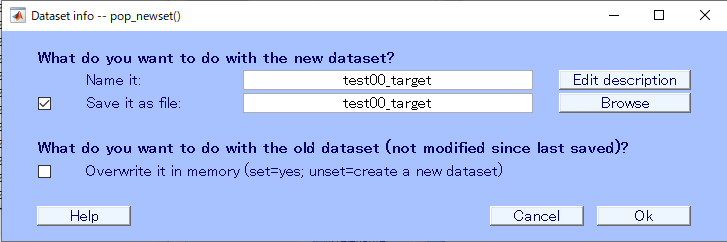
3.出力
あとは、EEGLABから出力すればOKです。
File -> Export -> Data and ICA activity to text file

Export data ウィンドウが表示されたら、一番上のOutput file nameのところで出力先を設定して、Export ERP average instead of trialsにチェックを入れて、OKします。
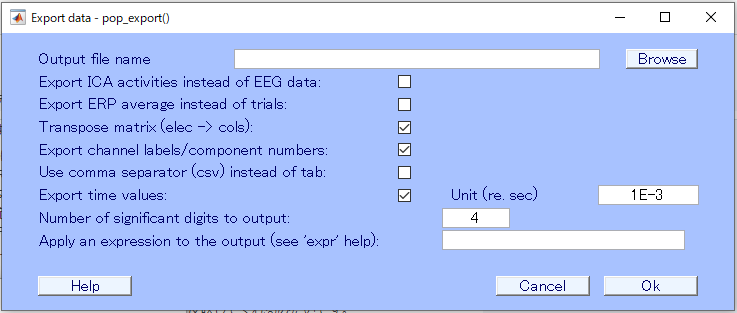
そうすると、出力先フォルダにERPのデータが保存されます!
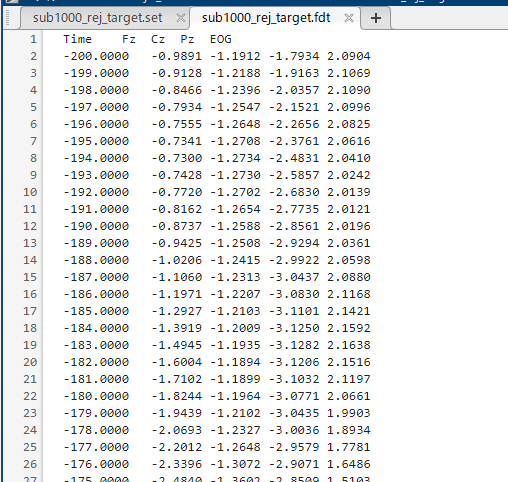
.fdtファイルで保存されるので、エクセルで開くことが出来ます!
お疲れ様でした(^^)/
これで、とりあえずの分析は完了です!!
まずは、手作業でできるようになっておいて、そのうち全部自動化も計画したいと思います!!
EEGLABで脳波解析に挑戦③

EEGLABで脳波解析をしていますが、途中で知っておくと良さそうなことをいくつかメモしているので、それもこちらにメモしておきます。
1.途中で保存したデータを読み込む

私は、分析の過程が長いので、定期的に名前をつけて保存をしています。
ところが先日、「あれ?」ちょっと前のところに戻りたい!と思った時に、どうやって前のファイルを読み込むんだっけ?と気が付きまして…。
ハズバンドに聞いてみました。
私は、file -> Import dataかと思っていたのですが、file -> load existing datasetでした!
忘れないようにこちらにメモしておきます。
2.コードを書きだす
これまで、コードを書くなんて、ほとんどやったことがなかったんですが、コードを書けるとできることも広がるんですよね。
最近、少しコードの勉強もしているので、自分がEEGLABのウィンドウでやっていることを、コードで保存しておくと良いということがちょっと理解できました。
これは、とっても簡単で、何かやった後で、MATLABのコマンドウィンドウにeeghと入力して、Enterを押すだけです。

今回は、データの読み込みをしただけなので、こんなコードがでてきました。

自分のデータの分析の方法が決まったら、こうやってコードを記録して、どのコードが何をしているのかも書いておくと、後から振り返って確認をする時に便利ですね。
3.間違えてちょっと戻りたいとき
EEGLABで処理をしたんだけど、1つ前の保存したところに戻りたいときには、Datasetsをクリックすると、どこに戻るとか選択して選べます。

こういうのも、10年前にやっていた時は、よくやっていましたが、すっかり忘れちゃっていましたー!
昨日、試行錯誤していて、あ!ここだ!と見つけました笑
簡単なことばっかりだけど、忘れないようにメモしておきますね。
HRのデータを保存します!

夏休みにPolarを使って収録したHRのデータを取り出す作業にようやく着手しました笑
他にもやらねばならないことや、やりたいこともあって、ずっと寝かしてしまっていました。が、あのデータって…どのくらい保存されているんだろう…?と、心配になり、やっぱり早めにとりだそうと、動き出しました。
当初、取り出し方も分からず、何日も試行錯誤していたのですが、お問合せ窓口に問い合わせ、無事取り出し方もわかっていますので、後は手を動かすだけというところです。
せっかくなので、取り出すやり方もここに書いておきます!
1.PolarをPCに接続します!
これはもう超簡単で、USBを挿すだけの簡単な作業です。
2.Polar FlowSyncというウィンドウを起動します!
といっても、最初に公式サイトでPolar Flowというソフトをダウンロードしておくと、USBを挿すだけで勝手にこのウィンドウが起動するんです。

勝手に同期がはじまります。

同期はすぐに完了しましたが、しばらくほったらかしにしていたので、バッテリー充電中です。

3.ブラウザが起動して、Polar Flowのページが開きます。
しばらく待つと、勝手にPolar Flowのダイアリーのページが開きます。
(アカウントを登録している場合は、時計と対応するIDでサインインする必要があります。)

4.データを取り出します。
実験した7月のデータから取り出すので、◀を押して7月を表示しました。
30日のところに、ちゃんとデータがあります(良かったです)。

この、取り出したい日付のところの、人のマークのところをクリックします。

すると、この日収録したすべてのデータが表示されます。

欲しい部分だけ切り取って保存することもできますが、一旦すべてのデータを取り出そうと思うので、一番下のセッションのエクスポートをクリックします。

これで、保存したい形式を選びます。
そうすると、ダウンロードフォルダにCSVファイルがダウンロードされます。
開くとこんな感じです。

分析はそのうちやるとして、今日はすべてのデータを取り出す作業をします!!
頑張るぞー!!